网站的内容这块 有时间许多的东西需要去处理。。。。
例如网站有上千个产品需要改版或者更换CMS。。。。
那么就要去处理里面的数据了。。。。。
当然你可以去人工操作。。。。 不过那样费时费力 还会眼花的哦。。。。。
那么现在 可以借助一些工具去实现智能了。。。。
一:可以使用一些CMS自带的采集模块。例如DEDECMS,PHPCMS,PHP168都自带采集功能
二:使用专用的采集工具。例如火车采集,狂人采集等。
当然现在我是选择的后者了,首先前者通过Browser来获取的效率方面不够高,而且经过长时间运行,悲剧的浏览器可能会假死。
以下用一个实例来演示下了。
任务计划:采集sina博客娱乐版块的明星日志栏目:http://roll.ent.sina.com.cn/blog/star/index.shtml
这里,页面很简洁,能提高不少采集器的工作效率。
首先在火车采集站点下建立一个任务,这点操作很简单,就不详述了。
如下设置: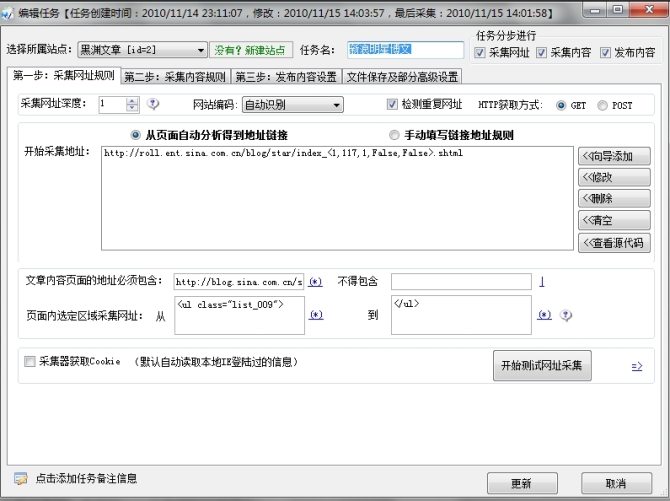
上图中:首先要有一个任务名:其次就是添加采集地址,也就是页面列表的,可以使用(*)变量替换。
页面的选定区域就是指定的首位的特征符即可,当然,也可以如上加上地址必须包括选项啊。
以上设置完毕以后就可以点击开始测试网址采集了。如果采集正常就没什么问题了。
选择第二步:
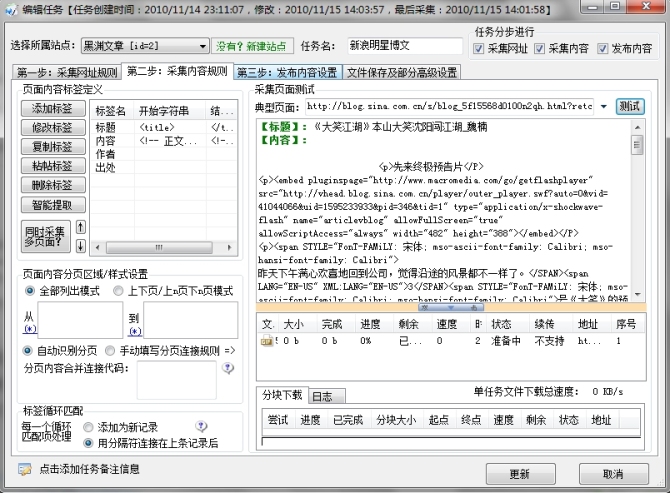
这里可以找一片文章地址测试下。
这边要注意的就是文章内容的设置:
可以看下图:
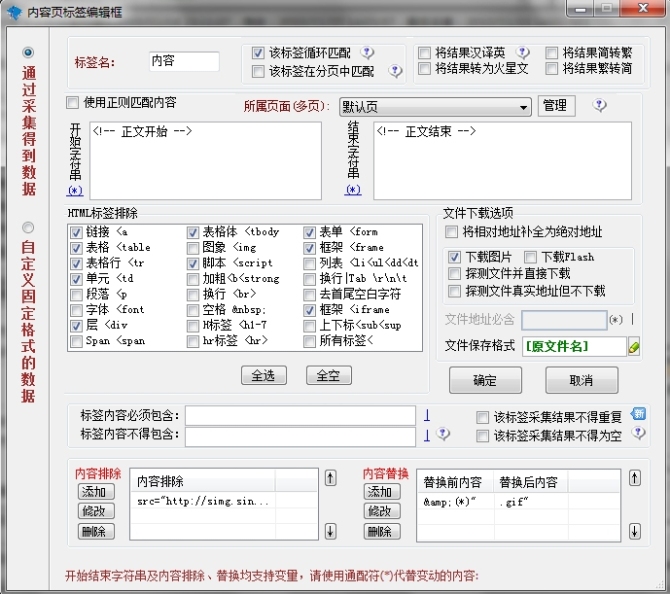
这里要注意对文章的内容的过滤规则, 我需要下载图片所以就勾上了图片了,包括文件名字也可以改的。
新浪这里对采集做了防盗链。 例如此文:http://blog.sina.com.cn/s/blog_5f15568d0100n2qh.html?retcode=0
可以看如下代码:

我这里过滤了文章的A标记 以及去除了线画的那段,就是防止盗链的,正常情况下浏览器解析的是src标记,除非用js触发否则那真实real_src的路径就被屏蔽了。
其次,我用训了做了实验,文章中的图片,例如:http://static3.photo.sina.com.cn/middle/48661154h951114b35e42&690 改成后缀是.jpg或者gif都能正常显示,不大懂。
所以这个地方采集器也不懂,就替换了下内容, 把&(*)”替换成了.gif。这时候采集器就正常解析和探测下载文件了。
这里需要说明的是 &(*)”原本是 &000″,里面的三个零也是变量,所该就用(*)通配替换了。
这里OK 可以换几篇文章测试下过滤的通用性。 不让就和我一样的郁闷了,采集了好几千条发布后错误的悲剧了。
发布这一块就不说了,需要了解上火车官网。
需要说的是下面 最后一步的文件保存。
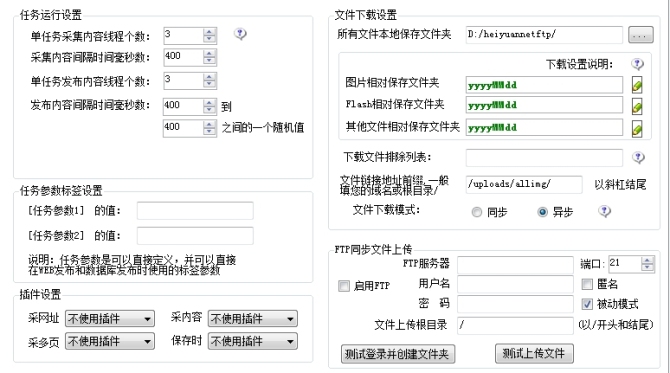
这里需要注意的就是文件前缀和保存文件夹。
如上设置的是符合dedecms的存储方式。 yyyyMMdd 就是年月日 如:20101115 方便分类。
/uploads/allimg/就是文件的相对路径。 别忘了后面还有个 yyyyMMdd .
例如2010年11月15日采集的文件名叫:hycms.jpg
那么相对路径就是 /uploads/allimg/20101115/hycms.jpg
绝对路径:http://www.heiyuan.net/uploads/allimg/20101115/hycms.jpg
最后需要注意的就是左边采集运行设置参数:尽量设置大一点,否则会出现采集失败,或者采集不全的问题。
哎 悲剧啊 我用的免费版本的 不支持上传文件,和采集失败的文件。
求赞助啊。。。
好了 这里最后别忘了点击下更新按钮。 尽情的开采吧。。。。
原文:风黑的大地 所有 欢迎转载 项目合作QQ:373653015。